The Data Еnignеering field is a relatively a new area of IT,
which is actively developing within the last years.
The field is dynamically changing, and those changes also reflect in the emerging
approaches in the architecture. In this article we will briefly cover some of
the most popular DWH architectures.
Independent Data Mart Architecture
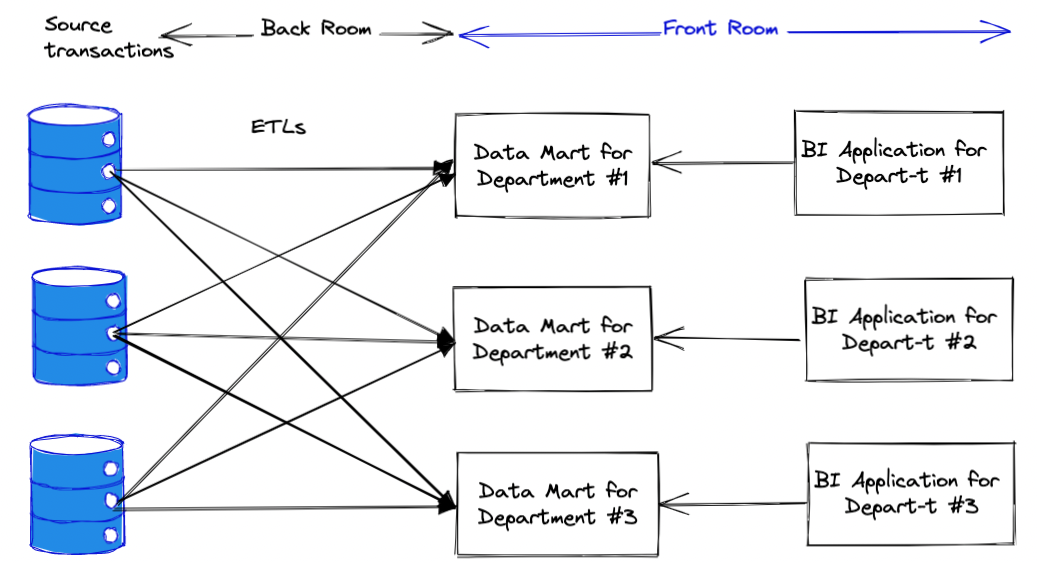 In this architecture, the data marts are highly adjusted to the needs of
the specific departments. Each data mart is significantly customised per
department case. The situation when different departments repeat the work
of other department in a slightly different way is quite typical for this
architecture. As a consequence, when two department are discussing a certain
KPI they usually do not match to each other (since they are cacluclated in
a slightly different way), which is a source of various
conflicts and misunderstandings between the departments.
The Independent Data Marts have one key benefit, the development of
the Marts does not require time-consuming communication across departments.
The latter is a big time-saver in many corporate environments.
In this architecture, the data marts are highly adjusted to the needs of
the specific departments. Each data mart is significantly customised per
department case. The situation when different departments repeat the work
of other department in a slightly different way is quite typical for this
architecture. As a consequence, when two department are discussing a certain
KPI they usually do not match to each other (since they are cacluclated in
a slightly different way), which is a source of various
conflicts and misunderstandings between the departments.
The Independent Data Marts have one key benefit, the development of
the Marts does not require time-consuming communication across departments.
The latter is a big time-saver in many corporate environments.
Hub-and-Spoke Corporate Information Factory
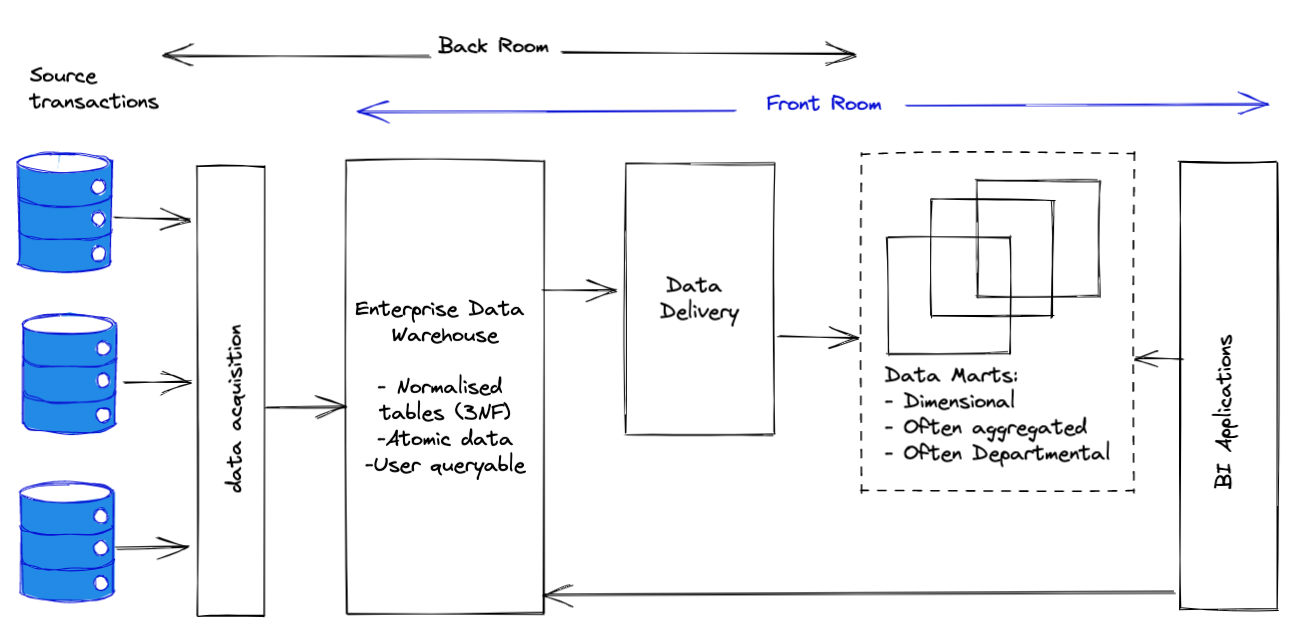 The Hub-and-Spoke Corporate Information Factory (CIF) is an approach advocated by
Bill Inmon. In this architecture, the data from all of the operational sources
first gets accumulated in a data layer which is called Enterprise Data Warehouse
(EDW). The data in EDW is always kept in 3-d normal form (3NF). The normalisation in
the EDW is a mandatory process in CIF architecture.
The subsequent data delivery processes usually convert the data from 3NF to the
dimensional models. But unlike the Kimballs dimensional modeling the models
in the Hub-and-Spoke architecture are Department-centric.
Thus, the Hub-and-Spoke has cons similar to Independent Data Marts- repeated
work in various departments, missmatching KPIs across departments, etc.
Additionally, it has yet another data layer EDW, that adds more complexity
on maintainance than solves the integrational issues.
The Hub-and-Spoke Corporate Information Factory (CIF) is an approach advocated by
Bill Inmon. In this architecture, the data from all of the operational sources
first gets accumulated in a data layer which is called Enterprise Data Warehouse
(EDW). The data in EDW is always kept in 3-d normal form (3NF). The normalisation in
the EDW is a mandatory process in CIF architecture.
The subsequent data delivery processes usually convert the data from 3NF to the
dimensional models. But unlike the Kimballs dimensional modeling the models
in the Hub-and-Spoke architecture are Department-centric.
Thus, the Hub-and-Spoke has cons similar to Independent Data Marts- repeated
work in various departments, missmatching KPIs across departments, etc.
Additionally, it has yet another data layer EDW, that adds more complexity
on maintainance than solves the integrational issues.
Kimballs Dimensional modeling
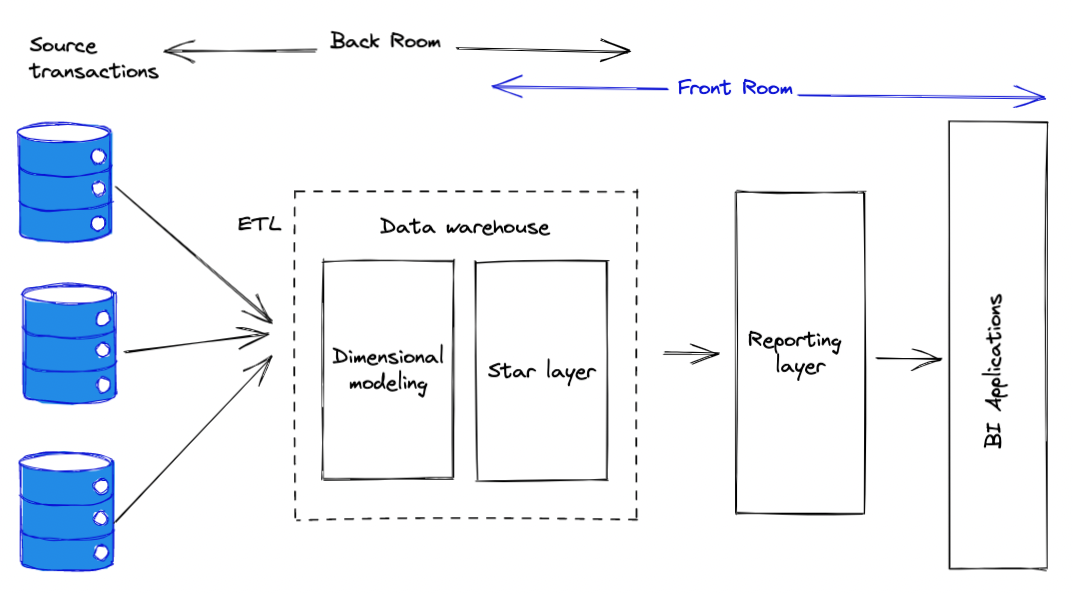 In this architecture, proposed by Kimball the data processing is broken down
into two major steps:
In this architecture, proposed by Kimball the data processing is broken down
into two major steps:
- the backroom extract, where the data is collected from the operations sources
- the transformation and load environment
- the front room with representation area.
The key difference of the Kimballs approach is that the data models are build around the business processes. Unlike the Department-centric architectures, the focus on the business processes helps to avoid the code and data duplication. It also prevents the cases when the KPIs are not matching between departments. Additionally, the star-schemas in Kimballs architecture provide the required flexibility when it comes to the reporting, and advance analytix.
The Labmda architecture
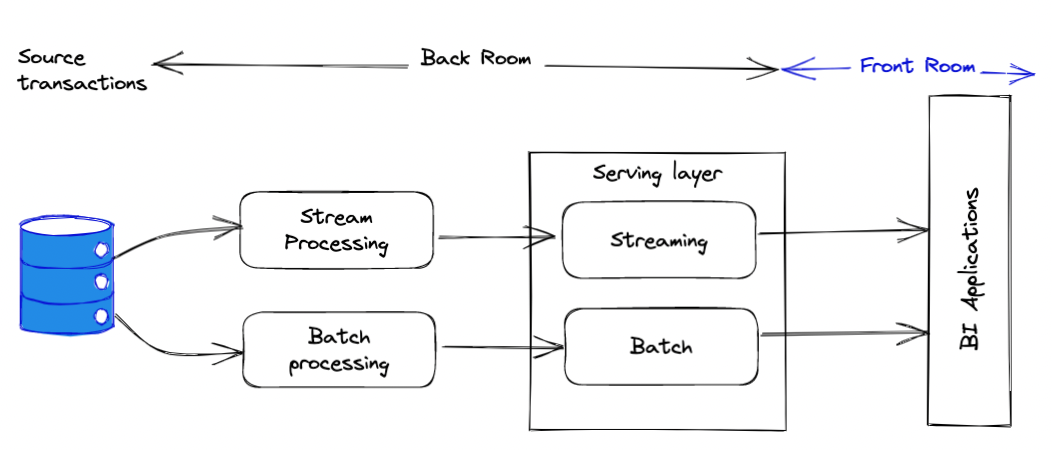 The raise of the labmda architecture correlates with the growth of the Big Data.
Particularly, with the emerge of the MapReduce solutions.
The Lambda architecture was significantly dictated by the business
willing to having access to the most latest data possible as well as having
a long and accurate history.
The raise of the labmda architecture correlates with the growth of the Big Data.
Particularly, with the emerge of the MapReduce solutions.
The Lambda architecture was significantly dictated by the business
willing to having access to the most latest data possible as well as having
a long and accurate history.
In this architecture, the streaming part is in charge of delivering the most recent values. While the batch processing takes care of the long term reports. Typically, the streaming and processing would require completely different set of tools like ETL frameworks and Databases. Namely, for the streaming part a NoSQL database like Mongo would have a good fit accompanied with streaming tools like Kafka, PubSub or RabbitMQ. While for the batch processing the teams would use Spark, HDFS, BigQuery, SnowFlake or Redshift. So different set of tools would obviously require from the team a lot of effort on the maintainance. Since every change needs to be reflected in two independent places. In the mordern tools like Spark and DataFlow (apache beam) the boundaries between the streaming and batch processing are vanishing. The recent versions of Sparks allow to write stream processing, while DataFlow makes it possible to port the streaming processing to the batch processing with minimal changes.
Kappa architecture
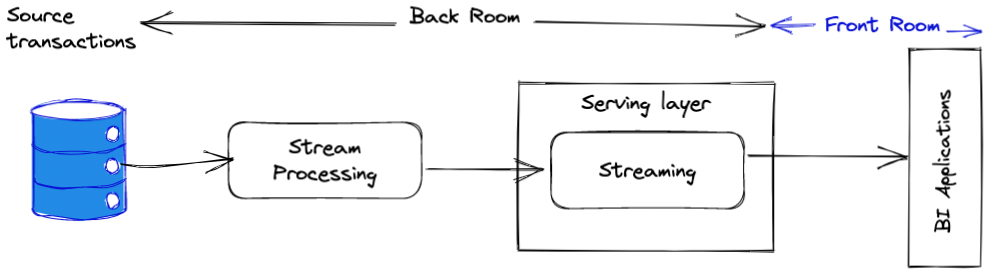 Kappa architecture emerged after when the industry realised the main cons of the
lambda architecture. Namely, the need to maintain two separate code bases with
separate stack of technologies. Since this setup makes the maintainance
highly complicated, time-consuming and error-prone.
The idea behind the Kappa architecture was to use the same stack of thechnologies
and same pipelines that would be able to work both in streaming and batch modes.
Typically, the Kappa architecture is based on Kafka queues where the that is
able to persist the stream of data for a period of time. The messages in the queue
can be processed as they arrive - streaming mode. Or, as a relatively big chunks-
the batch mode. The code base used to consume the messages in both modes is the same,
with slight adjustments.
Another benefit, that this architecture provides is that the engineers are able to
re-run the pipelines on the already processed data, by moving the pointer back in
time, thanks to the Kafka peristent queues. This comes in handy when a bug in
code might break the output results and reverted or fixed code can be
simply rescheduled.
The main downside of this architecture is it’s complexity and the costs.
Kappa architecture emerged after when the industry realised the main cons of the
lambda architecture. Namely, the need to maintain two separate code bases with
separate stack of technologies. Since this setup makes the maintainance
highly complicated, time-consuming and error-prone.
The idea behind the Kappa architecture was to use the same stack of thechnologies
and same pipelines that would be able to work both in streaming and batch modes.
Typically, the Kappa architecture is based on Kafka queues where the that is
able to persist the stream of data for a period of time. The messages in the queue
can be processed as they arrive - streaming mode. Or, as a relatively big chunks-
the batch mode. The code base used to consume the messages in both modes is the same,
with slight adjustments.
Another benefit, that this architecture provides is that the engineers are able to
re-run the pipelines on the already processed data, by moving the pointer back in
time, thanks to the Kafka peristent queues. This comes in handy when a bug in
code might break the output results and reverted or fixed code can be
simply rescheduled.
The main downside of this architecture is it’s complexity and the costs.
Data mesh
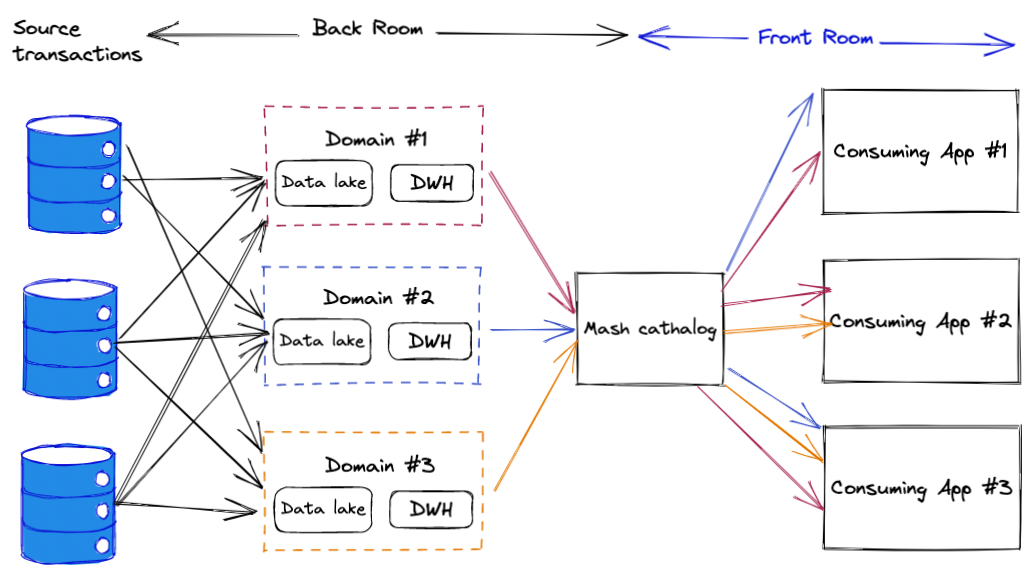 The data mesh architecture came out as a response to the classical centralised
data lakes and data warehouses. Data mesh instead is focused on decentralised data warehouses built around
the business-domains. The domain driven design is commonly used in software
architecture, data mesh is applying it to the data engineering space.
Here are some main points about the main conepts of the Data mesh:
The data mesh architecture came out as a response to the classical centralised
data lakes and data warehouses. Data mesh instead is focused on decentralised data warehouses built around
the business-domains. The domain driven design is commonly used in software
architecture, data mesh is applying it to the data engineering space.
Here are some main points about the main conepts of the Data mesh:
- Domain-oriented decentralised data ownership and architecture
- Data as a product
- Self-serve data infrastructure as a platform
- Federated computational governance
Lakehouse
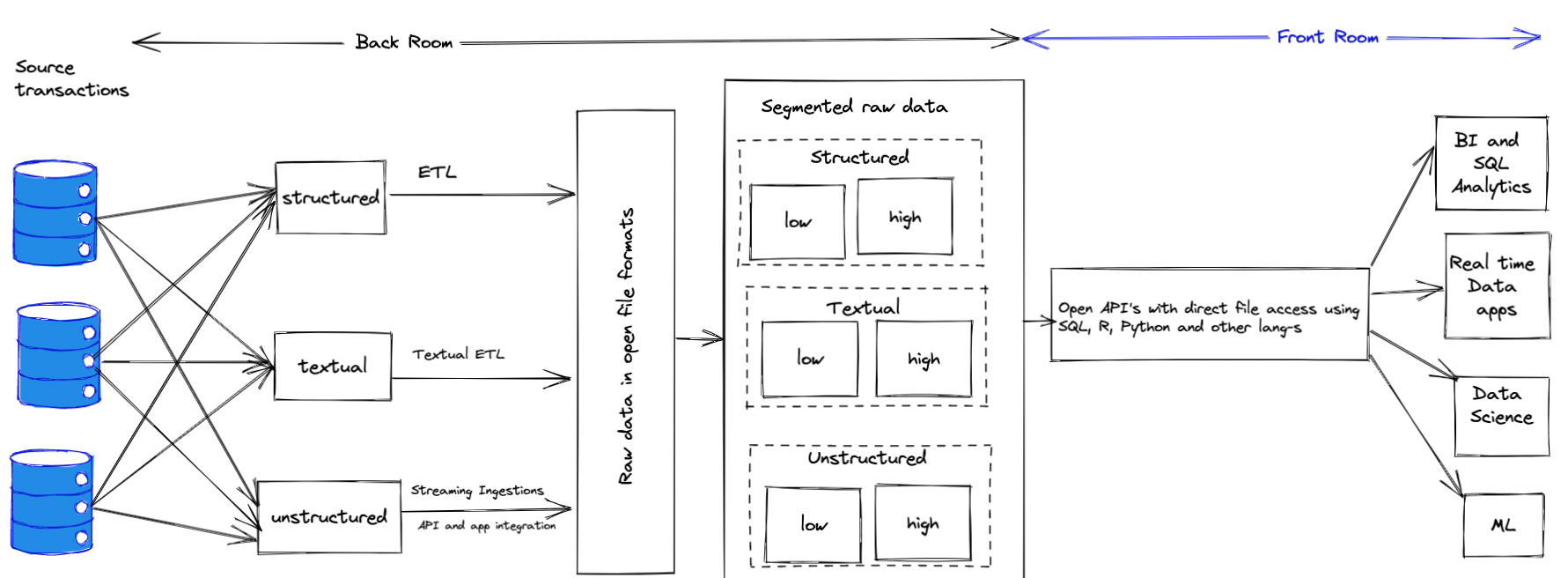 One of the architectures that got a lot of attention in the recent years.
The lakehouse provides layers of data arrangements that creates a similar to data warhouse
experience, while keeping the data in object storage.
It combines the approaches used in the classic data warehouse, like
schema management, strict table structures, incremental updates, rollbacks and table history
and at the same time keeps the data in a raw object storage format typical for
the data lakes. The fact that the data is stored in a raw format,
provides a common ground which is required when a proprietary format is used by a storage.
Additionally, lakehouse architecture makes the data accessible in a near realtime
for the analytical tools.
It is also worth to mention that much of the data in a lakehouse might not have a
table structure imposed. The overhead of table structure maintainance might be added
only in the cases where it is required, the rest will be stored in a raw format, saving
both the storage and the cots.
In fact, many data warehouse solutions like BigQuery or Snowflake, do store the data in
a similar manner, but hide the comlexity of the files and metadata storage
management from the end user.
One of the architectures that got a lot of attention in the recent years.
The lakehouse provides layers of data arrangements that creates a similar to data warhouse
experience, while keeping the data in object storage.
It combines the approaches used in the classic data warehouse, like
schema management, strict table structures, incremental updates, rollbacks and table history
and at the same time keeps the data in a raw object storage format typical for
the data lakes. The fact that the data is stored in a raw format,
provides a common ground which is required when a proprietary format is used by a storage.
Additionally, lakehouse architecture makes the data accessible in a near realtime
for the analytical tools.
It is also worth to mention that much of the data in a lakehouse might not have a
table structure imposed. The overhead of table structure maintainance might be added
only in the cases where it is required, the rest will be stored in a raw format, saving
both the storage and the cots.
In fact, many data warehouse solutions like BigQuery or Snowflake, do store the data in
a similar manner, but hide the comlexity of the files and metadata storage
management from the end user.
Summary
Although, a good architecture is vital for any data warehouse solution, it is really hard not only to engineer a good architecture, but even to define, what a good architecture looks like. We can dive deep into details of how to define a good architecture, but I prefer a much simple approach- typically u can simply see it when an architecure is good. There multiple approaches of how to engineer the architecure, in this article we just briefly touched a surface of several architectural designs. In practice, you would need find an architecture that feet the best for your particular case, mb a combination of multiple approaches would be required. Again, it significantly depends on a case. Thus, take your time, start with building high level view of the all the components, and try to find the best techinques that fit your case.